
Fangxun Shu


Fangxun Shu
I am currently working at Bytedance, collaborating with Prof. Si Liu, Hongsheng Li, and Cihang Xie. My research primarily focuses on efficient multimodal large language models (MLLMs), exploring innovative architectures such as Mixture of Experts (MoE) to enhance model scalability and efficiency, as well as advanced training paradigms such as knowledge distillation to optimize performance while reducing computational costs. Ultimately, I aim to create powerful yet resource-efficient models that push the boundaries of multimodal intelligence.
Experiences
Publications
Full Publications: Google Scholar
-
LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
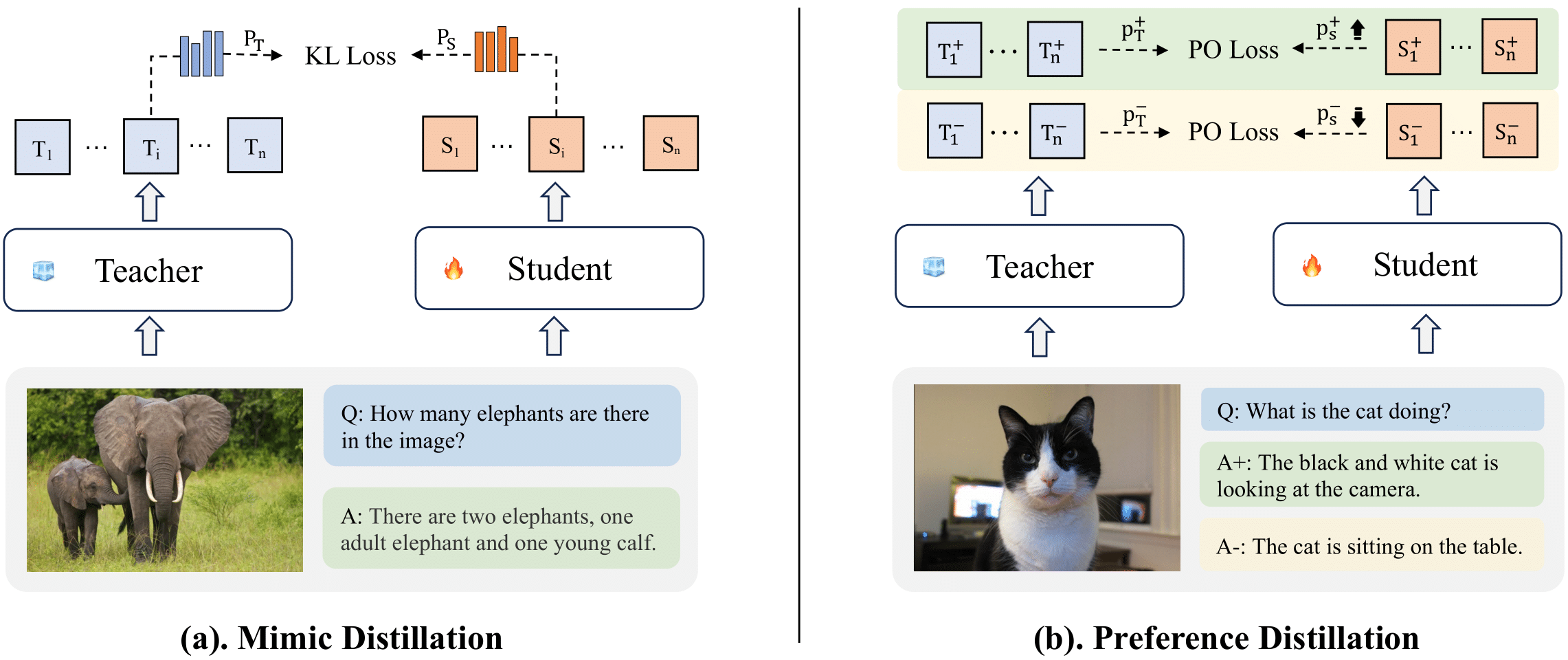
Fangxun Shu, Yue Liao, Le Zhuo, Chenning Xu, Lei Zhang, Guanghao Zhang, Haonan Shi,
Long Chen, Tao Zhong, Wanggui He, Siming Fu, Haoyuan Li, Si Liu, Hongsheng Li, Hao Jiang
arXiv / code
International Conference on Learning Representations (ICLR), 2025
-
MAC: Masked Contrastive Pre-Training for Efficient Video-Text Retrieval
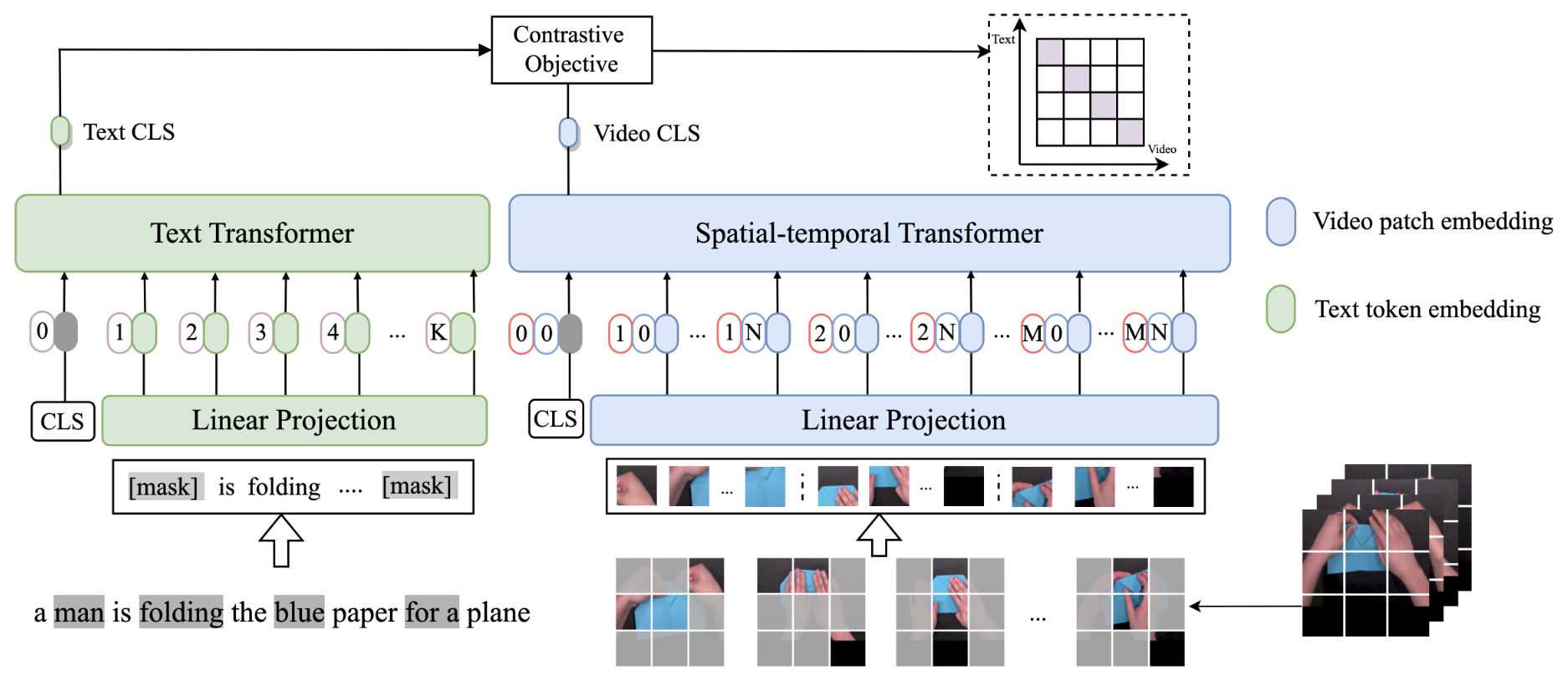
Fangxun Shu, Biaolong Chen, Yue Liao, Jinqiao Wang, Si Liu
camera-ready
IEEE Transactions on Multimedia (TMM), 2024
-
Audio-Visual LLM for Video Understanding
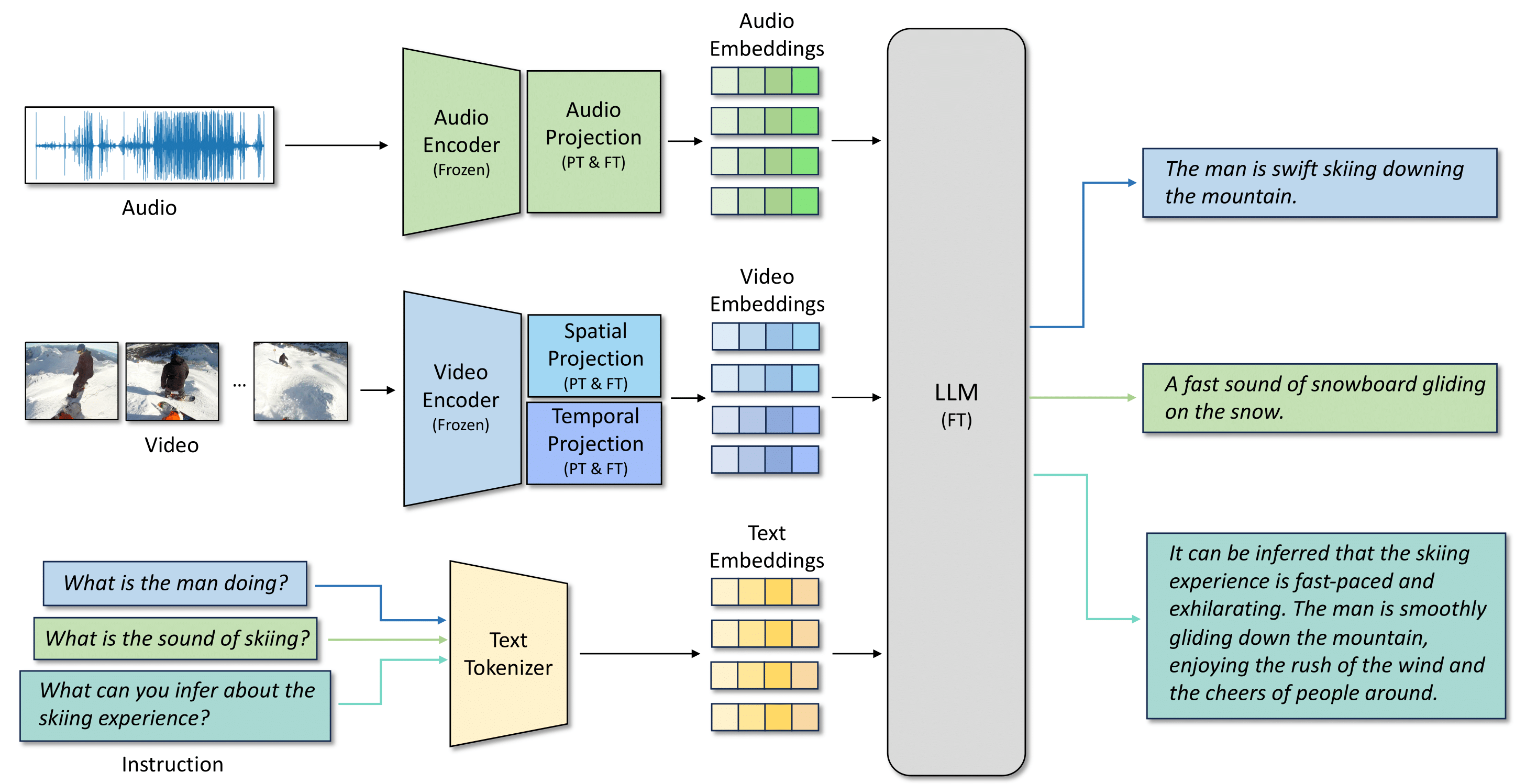
Fangxun Shu, Lei Zhang, Hao Jiang, Cihang Xie
arXiv
ICCV What is Next in Multimodal Foundation Models Workshop, 2025
-
Filter & Align: Leveraging Human Knowledge to Curate Image-Text Data
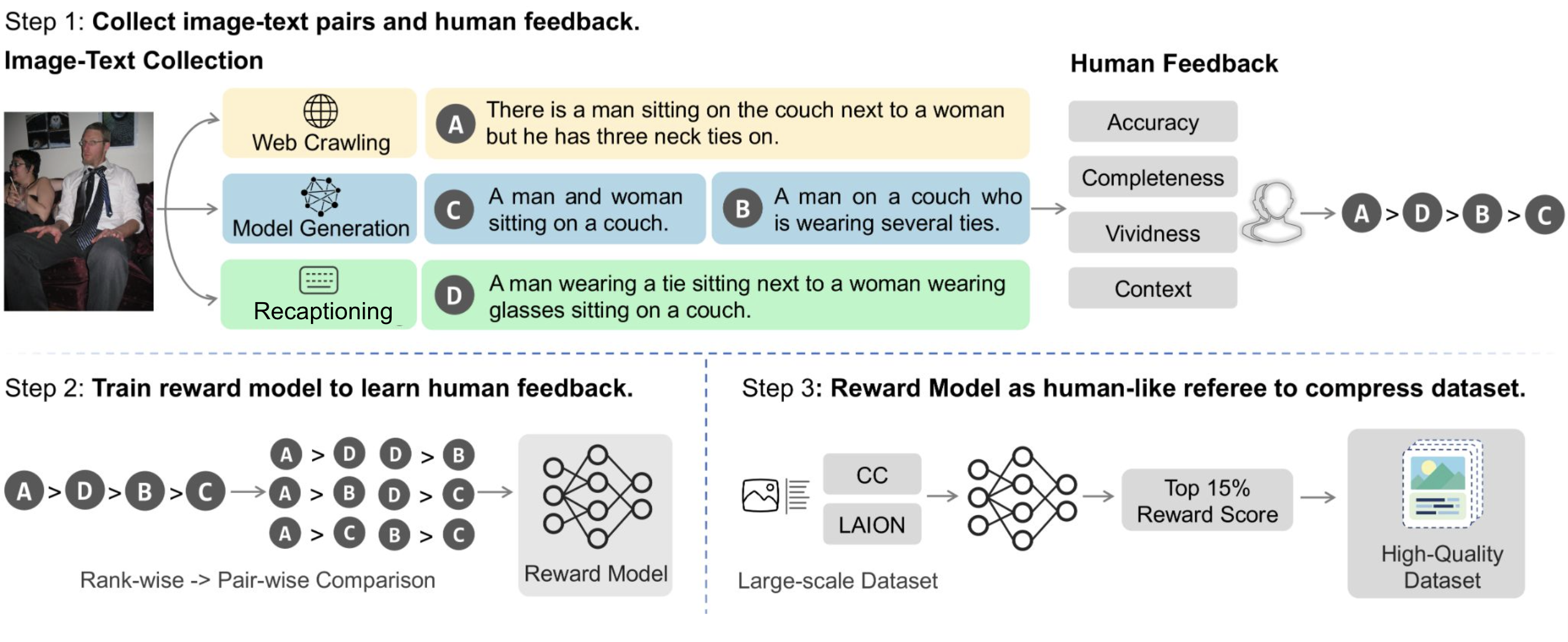
Lei Zhang*, Fangxun Shu*, Tianyang Liu, Sucheng Ren, Hao Jiang, Cihang Xie
arXiv
Tech report, 2024
-
MARS: Mixture of Auto-Regressive Models for Fine-grained Text-to-image Synthesis
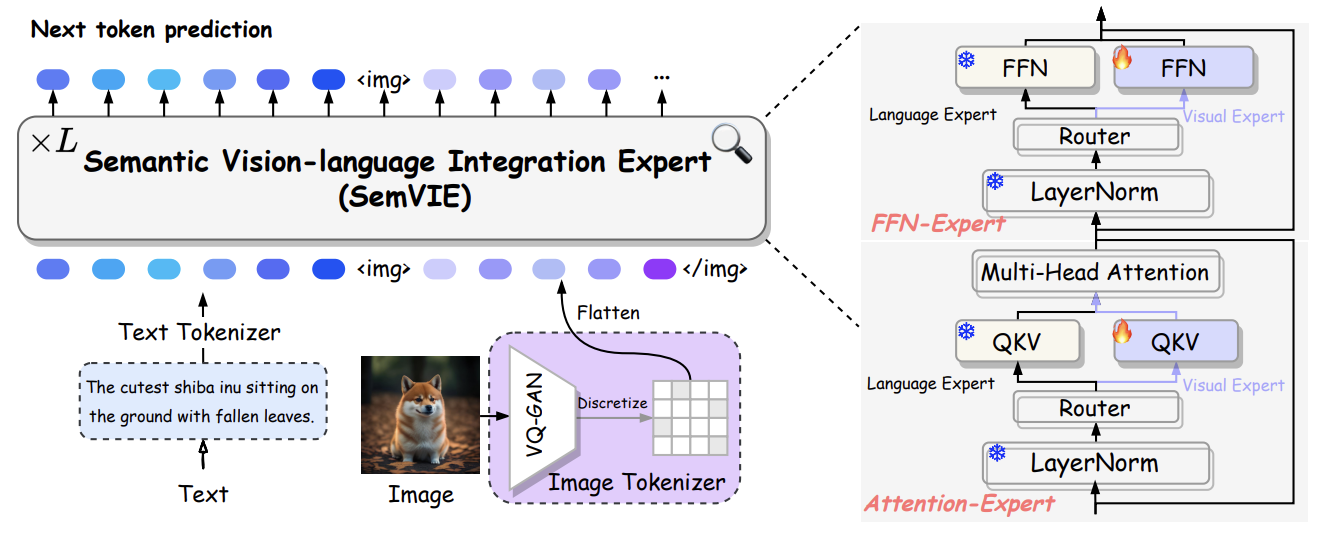
Wanggui He*, Siming Fu*, Mushui Liu*, Xierui Wang*, Wenyi Xiao*, Fangxun Shu*, Yi Wang,
Lei Zhang, Zhelun Yu, Haoyuan Li, Ziwei Huang, LeiLei Gan, Hao Jiang
arXiv
AAAI Conference on Artificial Intelligence (AAAI), 2025
Interests
Mulitimodal Large Language Models, including: (1) efficient architecture design and training paradigm (2) effective alignment and reasoning.
Services
Reviewer for CVPR, ICLR, NIPS,and ICML.
